
Свет в окошке
| « Наша служба и опасна и трудна, и на первый взгляд как-будто не видна | Праздничный подарок от Израиля Соломоновича! » |
Compreno от ABBYY (статья в Компьютерре) |
||||
|
Проект Compreno, над которым компания ABBYY корпит уже пятнадцать лет и выводит, дай бог, в этом году на стадию готового к потреблению продукта — это не новое, и тем более — не очередное событие. Автор: Сергей Голубицкий | Раздел: Голубятня | Дата: 28 февраля 2012 года Больше всего на свете мне хочется выделить тему сегодняшнего рассказа из потока рядовых событий IT, которыми заполняется информационное пространство моей колонки. Новые гаджеты — это замечательно. Новый удачный софт -бальзам на истерзанную душу пользователя. Проект Compreno, над которым компания ABBYY корпит уже 15 лет и выводит, дай бог, в этом году на стадию готового к потреблению продукта — это не новое, и тем более — не очередное событие. Compreno — это полноценная, не имеющая аналогов в истории технологическая революция. Масштаб этой революции, значение ее для людей (именно для всех людей, а не только для любителей компьютеров) сопоставимы разве что с изобретением World Wide Web или электронной почты. Никак не меньше. Для наглядности можно перевести эту революцию в понятные материально-купюрные реалии: если ABBYY спокойно, без суеты коммерциализирует Compreno хотя бы в десятой части возможных ее практических применений, а затем выйдет на фондовый рынок, капитализация компании затмит всех кумиров сегодняшнего дня — от Apple, грамотно и стильно эксплуатирующего весьма и весьма посредственные в технологическом отношении решения, до Google, умудряющегося заводить в тупик охапками большую часть собственных перспективных начинаний.
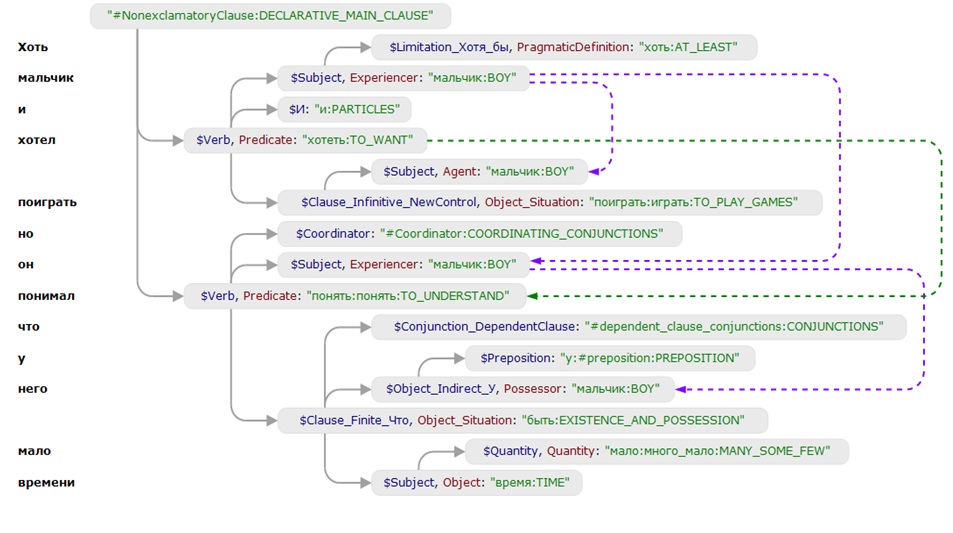
Впрочем, довольно авансов и эмоций (хотя завсегдатаев Голубятен ни тем, ни другим давно не удивишь ☺ — пора представить Compreno во всем его величии. Начну с лапидарного компендиума: Compreno — это технология перевода любого человеческого языка на универсальный язык понятий. Соответственно, Compreno включает в себя и сам этот универсальный язык понятий, который ABBYY 15 лет (тайком ☺ разрабатывала в своих исследовательских лабораториях. Результат ошеломляет: Универсальная Семантическая Иерархия (УСИ) — ядро языка понятий — насчитывает сегодня 60 тысяч элементов в универсальном разделе когнитивной модели, 80 тысяч — в русском разделе, и 90 тысяч — в английском! Ничего даже отдаленного в мире не существует. Перспективы, которые открывает Compreno, безбрежны и разнообразны: — компьютеризированный перевод текста с любого языка на любой на качественном уровне, несопоставимым со всеми распространенными сегодня системами перевода; — полноценный интеллектуальный поиск без специализированного синтаксиса запросов (Поиск по смыслу, извлечение фактов и связей между объектами поиска/мониторинга; мониторинг компаний и персоналий и построение аналитических отчетов на основе параметров разного типа и др.); системы искусственного интеллекта самых разнообразных профилей и применений; — автоматическое распознавание речи; — классификация документов и поиск похожих документов по смыслу; — анализ тональности в мониторинге; — реферирование и аннотирование (написание краткого содержания длинных документов) и это только начало. За пару дней до своей индийской зимовки я встретился с Татьяной Даниэлян, заместителем директора по лингвистическим технологиям компании ABBYY, и Сергеем Андреевым, генеральным директором и президентом группы компаний ABBYY и на протяжении полных двух часов сидел, широко разинув рот и охая от восторга по мере того, как в мое сознание вливались подробности революционного проекта, подкрепленные полноценной демонстрацией действующего прототипа движков машинного перевода и системы интеллектуального поиска. Все то время, что Сергей и Татьяна, сами едва сдерживая восторг от собственных достижений, стягивали завесу тайны с Compreno, меня не покидало чувство того, что я участвую в каком-то акте добровольного промышленного шпионажа. Согласитесь, масштаб проекта ошеломляет: 15 лет интенсивной работы сотен людей, 50 миллионов долларов собственных инвестиций, совсем недавно усиленных сколковским грантом в 475 миллионов рублей. Вся компьютерная мощь головного офиса ABBYY (а он, поверьте на слово, ошеломляет: 6 этажей 7-этажногоогромного П-образного здания) в любую свободную минуту задействована для просчетов, необходимых для отладки и совершенствования Compreno, в первую очередь УСИ. Впрочем, шпионаж — это лишь в моей голове, поскольку, разумеется, беседа наша состоялась в момент, когда Abbyy вышла на финишную прямую и была готова раскрыть миру свои карты. Подробности Compreno я донесу читателям со слов Сергея Андреева и Татьяны Даниэлян — не потому, что не доверяю собственным суждениям, а потому что рассказ у обоих получился гладким и содержательным, зачем же плодить сущности? Начало разработки Compreno пришлось на 90е годы, когда в арсенале ABBYY (в те годы — еще BIT Software) уже числилось два ледокола: словари Lingvo и программа для распознавания текста FineReader. Продукты продавались по всему миру, были хитами и приносили стабильную прибыль — манна небесная для романтических проектов вроде Compreno, стресс которых не пережил бы ни один сторонний инвестор (вкладывать миллионы долларов в нечто совершенно революционное да к тому же и с неизвестными перспективами? а вдруг ничего не получится? нет уж увольте!). ABBYY обошлась без чужих денег и это спасло Compreno, позволив довести до победного конца проект со столь колоссальными материальными и людскими затратами. Успех обеспечил и правильный изначальный выбор направления для разработки системы автоматического перевода. В 90-е в мире правила одна королева — Rule-Based Translation Model, классическая модель перевода, основанная на ограниченном наборе готовых правил для некоторой пары языков. Одна из проблем RBTM — в накоплении все новых и новых правил, которые в какой-то момент просто начинают конфликтовать между собой. Анализируя предложение, мы можем применить разные комплекты правил, при этом машине неведомы приоритеты. Перевод, основанный на RBTM, как правило, не озабочен полным синтаксическим анализом: вместо него предложение делится на фреймы, на которые затем интерполируют существующие в системе правила для получения перевода. RBMT системы не учитывают семантику. В начале XXI века усилиями Google мир подсел на иглу нового алгоритма перевода — так называемой статистической модели. Основа СМ — наличие обширной базы разнонаправленных переводов. Мы задаем статистическому движку предложение для перевода, он ищет в базе данных как в словаре варианты уже существующих переводов аналогичного текста и после незначительных изменений выдает вполне приличный результат. Изменения не самые существенные. Предположим нам нужно перевести предложение «в комнате стоит красный стул», а в статистической базе уже есть переведенная фраза «в комнате стоит зеленый стол» — решение элементарно: берется уже существующий шаблон перевода и новые слова просто заменяются по словарю. Поскольку в СМ используются уже готовые человеческие переводы заведомо высокого качества, то на выходе получается весьма недурственный результат, ибо для осуществления перевода не нужно погружаться в синтаксис, специфику фразеологии конкретного языка и проч. Все замечательно, однако, лишь до тех пор, пока дело не касается переводов в направлениях с так называемым низким покрытием (скажем, каким-нибудь, румынско-русским или тайско-венгерским). Где брать аналоги? По словам Сергея Андреева опасность подстерегает также при уходе в предметные области на массовых направлениях, потому что параллельных текстов становится сильно меньше, чем в бытовой и разговорной тематике. Сочетание ухода в предметную область и не самого массового направления перевода приводит к слабым результатам. Скажем, IT. Казалось бы, какие сложности могут возникнуть у машинного перевода с текстом на тему информационных технологий? В самом деле — никаких, если мы занимаемся русско-английским переводом. Зато они тут же возникнут на русско-французской ниве! Статистическая база в этом направлении чрезвычайно скудная и лакуны возникают на каждом шагу. Выход в рамках СМ для подобных ситуаций найден лишь паллиативный: работая с языками / темами низкого покрытия в качестве посредника используется английский язык. То есть сперва делается перевод с русского на английский, а затем уже с английского на, скажем, румынский, или тайский. В результате получается очень заметное снижение качества перевода. Самое печальное, что проблема с плотностью покрытия в рамках СМ никак не решается принципиально. Единственный выход: нанять сотни тысяч переводчиков и заставить их заполнять лакуны по всем направлениям с низким статистическим покрытием. Как вы понимаете, никто это делать не сможет и не будет. Помимо сложностей с низкой плотностью переводов по направлениям, выпадающим из узкого мейнстрима, у СМ еще множество мелких изъянов. Например, статистическая модель совершенно убого справляется с переводами имен собственных. Многие помнят о переводе Ющенко, как Януковича, а России как Канады. Отрицание (частичка «не») — это очень сложное препятствие. Частичку «не» можно правильно позиционировать в результате лингвистического анализа текста, а СМ таковым не занимается. В результате предложения, содержащие отрицание, часто переводятся движками на статистической модели с точностью до наоборот. Как бы там ни было, ABBYY изначально отказалась от Rule Based Translation Model и замахнулась на систему компьютерного перевода нового поколения. Надо сказать, что придумывать особо ничего не требовалось. Универсальный язык понятий существует в структурной лингвистике в виде давней и несбыточной мечты еще со времен Людвига Витгенштейна. Даже Наум Хомский в своих ранних трудах лишь углублял существующую утопию. Проект Compreno исходил из трех основополагающих посылок: — использование качественного и бескомпромиссного синтаксического анализа. — создание универсальной когнитивной модели языка, возможность которой определяется аксиомой о том, что люди, хоть и живут в разных условиях и говорят на разных языках, однако в массе своей мыслят одинаково. Формы выражения мысли разные, а вот понятийный аппарат совпадает. — автоматизированное корпусное дообучение — лингвистические описания верифицируются и дополняются на основании статистической обработки корпусных данных. Исходя из этих посылок была сформулирована идея Универсальной Семантической Иерархии (УСИ), способной описывать явления от общего к частному. На составление этой иерархии у ABBYY и ушло 15 лет. Получилось то, что вы уже знаете: только на сегодняшний день 70 тысяч понятий в универсальной части когнитивной модели, более 80 тысяч — в русской, более 90 — в английской. Алгоритм машинного перевода, основанного на УСИ, выглядит следующим образом: — Лексический анализ текста (выделение слов, знаков препинания, цифр и прочих текстовых единиц); — Морфологический анализ (определение грамматических характеристик лексем); — Синтаксический анализ (установление структуры предложения); — Семантический анализ (выявление выражаемого значения в системе языка); — Синтез из универсальной семантической структуры предложения на выходном языке. В результате подбор слов для перевода осуществляется не напрямую из первого языка, а из понятийного набора, который, условно говоря, «висит» на той же ветке универсального семантического дерева, но только уже со стороны второго языка. Поскольку модель УСИ сквозная, нижестоящие элементы системы по иерархии наследуют признаки вышестоящих элементов. Это простое, казалось бы, обстоятельство позволяет добиваться беспрецедентной точности машинного перевода, поскольку каждое слово из переводимого предложения описывается максимальным набором понятийных эквивалентов, причем не только видового, но и родовых качеств на всех уровнях смысловой иерархии. В УСИ предусмотрены взаимосвязи между элементами структуры, относящимися к разным классам, и эти связи также структурированы и формализированы, что позволяет выполнять многоуровневый понятийный анализ текста, также повышающий качество перевода. В процессе создания УСИ разработчикам открылись неожиданные грани использования системы: помимо машинного перевода язык УСИ можно использовать в интеллектуальных смысловых поисках и, возможно, автоматическом распознавании речи на новом качественном уровне, который достигается за счет глубокой интеграции и взаимопроникновения синтаксиса и семантики в модели универсальной семантической иерархии. На альтернативных направлениях возникают, конечно, и свои сложности. Скажем, сегодня самым узким местом для глобального применения семантико-синтаксического анализа в массовых поисковых системах выступают очень высокие требования к компьютерным мощностям, необходимым для индексации информационных массивов на понятийном уровне. Требования эти несоизмеримо выше, чем при существующих формах традиционной индексации. Впрочем, уже сегодня методика семантико-синтаксического анализа может эффективно применяться (и применяется ABBYY — видел полностью функциональный прототип поискового движка собственными глазами) для более целенаправленного и узкого поиска в закрытых корпоративных системах. Мировых аналогов у Compreno сегодня нет, хотя в некоторых университетах и ведутся разработки в аналогичных направления. Однако фора в 15 лет, задействованные огромные человеческие ресурсы и материальные затраты позволяют надеяться, что ABBYY таки сумеет застолбить для себя эксклюзивное место первопроходца. На руку компании играет и то обстоятельство, что последние 10 лет подавляющая масса исследований в мире велась в русле статистической модели машинного перевода. За теоретическим введением в Compreno последовало более чем часовое погружение в демонстрацию работы движка компьютерного перевода, основанного на УСИ. Я сидел в одном из конференц-залов офиса ABBYY и непрестанно протирал глаза, все еще до конца не веря в услышанное и увиденного.
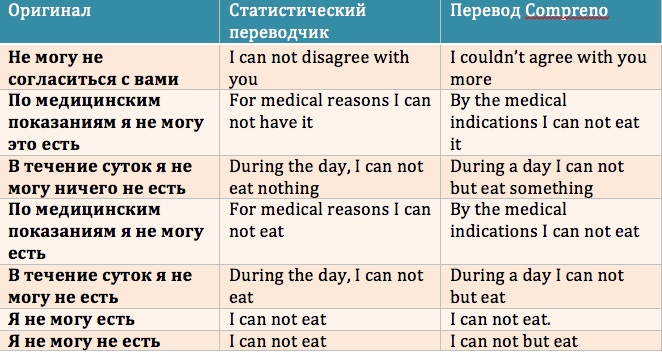
Теперь пользуюсь разрешением и демонстрирую читателям сравнение переводов, выданных Compreno и статистическим переводчиком (каким — гостеприимные хозяева просили не называть, но думаю, не маленькие и сами догадаетесь ☺ Не сомневаюсь, что для любого человека, знающего толк в переводах, это сравнение откроет новую вселенную. Вот работа статистического переводчика (разумеется, предложения подобранны специально «поддых», поскольку бьют в самые слабые места статистической модели перевода).
Это, господа, просто другой космос, другой уровень понимания текста. Это — революция! Смотрел я на это, слушал внимательно и, похоже, начал улавливать тайный смысл (шуточного) мотивационного плаката, висящего в одном из офисных коридоров ABBYY:
|
||||
|




Вы должны авторизоваться, чтобы оставлять комментарии.